路漫漫其修远兮,吾将上下而求索。 —— 屈原 《离骚》
文章已收录至精进Java编程系列 此系列其它文章 https://www.wormholestack.com/tag/java/
0. 序
本文开始前,提出几个问题,各位读者可以试着答答看。
- 计算机是如何执行程序代码的?
- Java是编译型语言还是解释型语言呢?
- Java代码的执行过程是怎么样的?
如果你对此还有些模糊,不妨看完本文。
作为许多知识底层原理的基础。本文将从计算机发展史说起,探究计算机执行程序的过程,并浅析Java程序执行原理,以开篇的几个常见问题为引,来达到巩固Java基础的目的。
只有足够了解程序本质,才会在编写代码的时得心应手。
1.计算机发展史
想了解计算机是如何程序的,我们首先应该对计算机有足够的了解。让我们了解计算机的发展,走进历史。
1.1 图灵机
在 1936 年,艾伦·图灵在论文《论可计算数及其在可判定性问题上的应用》中开创性地提出了计算机的通用逻辑模型 —— 图灵机模型。这一理论深刻地影响了第一代计算机科学家,更多能够实现计算功能的计算机被制造出来,图灵也因此被誉为 “计算机科学之父”。
图灵的基本思想是用机器来模拟人们用纸笔进行数学运算的过程。
下图为图灵机的简单示意图

图灵机的基本组成如下:
- 假设有一条无穷的【纸带】,纸带由一个个连续的格子组成,每个格子可以写入字符,纸带就好比内存,而纸带上的格子的字符就好比内存中的数据或程序;
- 有一个【读写头】,读写头可以读取纸带上任意格子的字符,也可以把字符写入到纸带的格子,同时可以编辑数据(写入或擦除),移动纸带向左或者向右;
读写头上有一些部件,比如存储单元、控制单元以及运算单元:
- 存储单元用于存放数据;
- 控制单元用于识别字符是数据还是指令,以及控制程序的流程等;
- 运算单元用于执行运算指令;
知道了图灵机的组成后,我们以简单数学运算的 1 + 2 作为例子,来看看它是怎么执行这行代码的。
- 首先,用读写头把 【1、2、+】这 3 个字符分别写入到纸带上的 3 个格子,然后读写头先停在 1 字符对应的格子上;
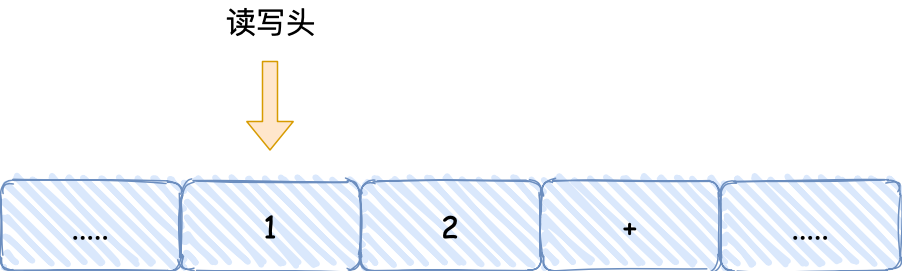
- 接着,读写头读入 1 到存储设备中,这个存储设备称为图灵机的状态;
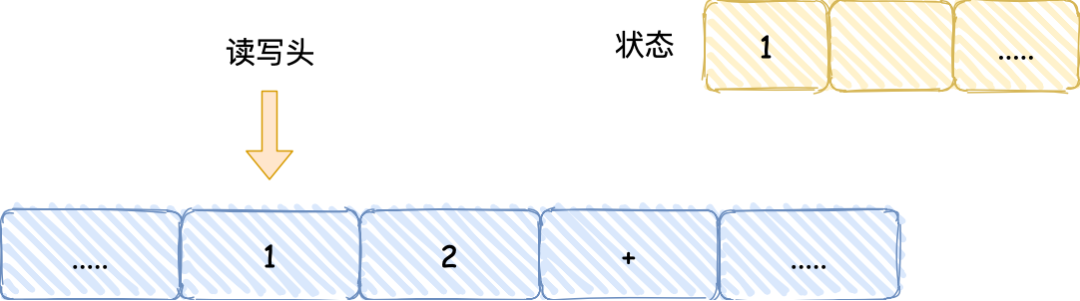
- 然后读写头向右移动一个格,用同样的方式把 2 读入到图灵机的状态,于是现在图灵机的状态中存储着两个连续的数字, 1 和 2;
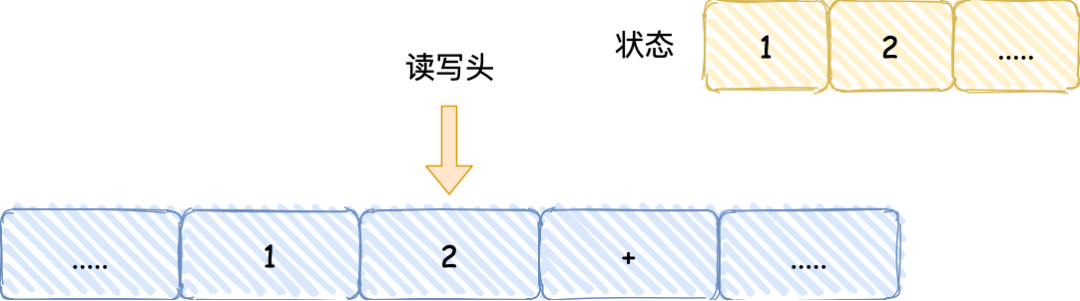
- 读写头再往右移动一个格,就会碰到 + 号,读写头读到 + 号后,将 + 号传输给【控制单元】,控制单元发现是一个 + 号而不是数字,所以没有存入到状态中,因为
+号是运算符指令,作用是加和目前的状态,于是通知【运算单元】工作。运算单元收到要加和状态中的值的通知后,就会把状态中的 1 和 2 读入并计算,再将计算的结果 3 存放到状态中;
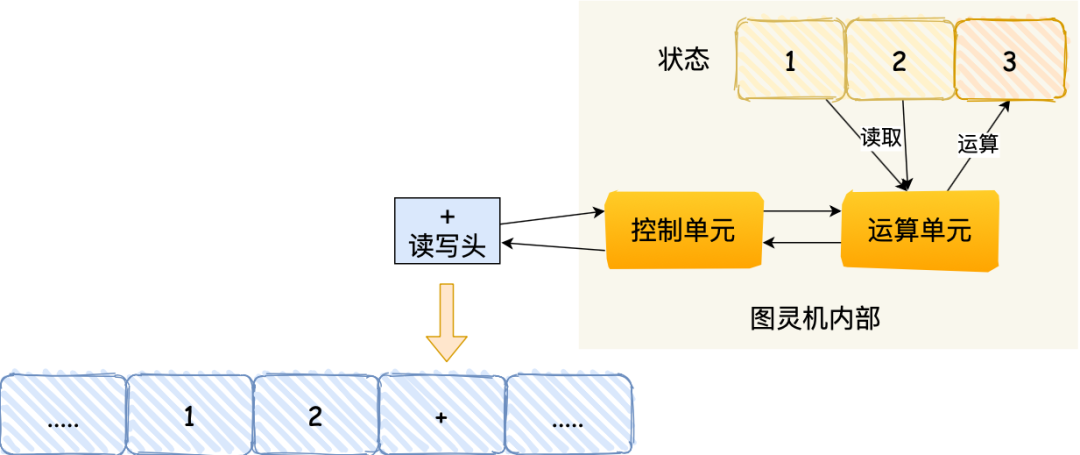
- 最后,运算单元将结果返回给控制单元,控制单元将结果传输给读写头,读写头向右移动,把结果 3 写入到纸带的格子中;
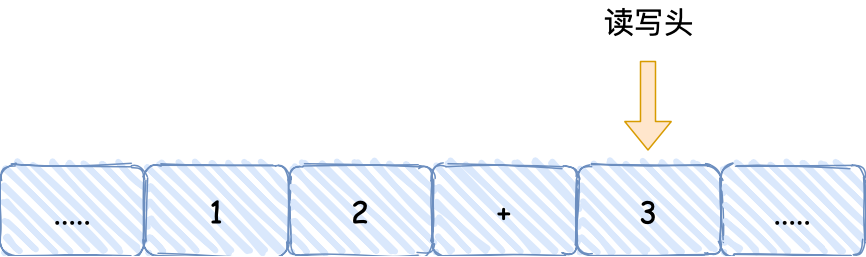
通过上面的图灵机计算 1 + 2 的过程,可以发现图灵机主要功能就是读取纸带格子中的内容,然后交给控制单元识别字符是数字还是运算符指令,如果是数字则存入到图灵机状态中,如果是运算符,则通知运算符单元读取状态中的数值进行计算,计算结果最终返回给读写头,读写头把结果写入到纸带的格子中。
事实上,图灵机这个看起来很简单的工作方式,但它可以模拟计算机的任何算法,无论这个算法有多复杂。
1.2 计算机的发展史
随着计算机的元器件从继电器升级到电子管(也叫真空管),计算机也从 “机电” 时代进入到 “电子” 时代。第一台电子计算机诞生了,它由各种门电路组成的,这些门电路通过组装出一个固定的电路板,来执行一个特定的程序,也就与其他早期的计算机一样,都是不可重新编程的
也就是说一台计算机只能执行一个特定的程序,如果需要修改程序功能,就需要将整个计算器拆开,然后重新组装电路。
1943 年,Colossus Mark I 计算机(巨人 1 号)在英国 Bletchley 公园(二战时的密码破译机构)被建造出来,以破解纳粹通信,好家伙一口气造了 10 台。 Colossus Mark I 被认为是第一台可编程的电子计算机,编程方法就是使用大量的开关和插线板(PlugBoards)。 但 Colossus Mark I 并不是通用计算机,它只被设计用于执行密码分析相关的计算。

直到 1946 年,John Mauchly 和 J. Presper Eckert 在美国宾夕法尼亚大学建造了 ENIAC(Electronic Numerical Integrator and Computer,中译:埃尼亚克), ENIAC 被认为是第一台可编程的通用电子计算机,也被认为是第一台现代意义上的计算机。 但是,ENIAC 和 Colossus Mark I 一样都使用插线板编程,虽然不需要拆掉整台计算机来重新编程,但是编程效率依然非常低,据说一个简单程序在 ENIAC 上编程最多要花费三个星期。
这对于早期异常昂贵的计算机来说,需要停机这么长时间来重新编程是无法接受的。人们迫切需要一种更高效更灵活的编程方式,有人开始研究 使用存储器来保存程序和程序处理的数据。
在 1944 年,ENIAC 的发明者之一 J. Presper Eckert 发明了一种基于水银管的存储器,这为后来的存储程序概念提供了实现基础。

在建造 ENIAC 的同时,Mauchly 和 Eckert 也在同步研究一种新设计 EDVAC,并向 John von Neumann(冯·诺依曼)提出咨询。冯·诺依曼也参与到 EDVAC 项目中,并且写了一份著名的内部文档 《First Draft of a Report on the EDVAC》 ,
在 1945 年冯诺依曼和其他计算机科学家们提出了计算机具体实现的报告,其遵循了图灵机的设计,详细阐述了 “存储程序计算机(Stored-program Computer)” 的概念,也就是人们所说的冯·诺依曼架构。
他们在 1947 年对 ENIAC 进行诸多改进,ENIAC 也成为了世界上第一台存储程序计算机。而 1948 年建造完成的 Manchester Baby 则被认为是世界上第一台基于冯·诺依曼架构的通用计算机。从 Baby 到现在 70 多年的时间,所有的单片机、PC 电脑、智能手机、服务器依然在遵循这一计算机架构。现代所有的计算机科学上的发展都是在软件和硬件能力上做优化,根本上的计算机架构依然没有改变。
冯·诺依曼也因而被誉为 “电子计算机之父”。
下面让我们具体了解下冯诺依曼模型。
1.3 冯诺依曼模型
冯.诺依曼结构中,将程序和数据一样看待,将程序编码为数据,然后与数据一同存放在存储器中,这样计算机就可以调用存储器中的程序来处理数据了。意味着,无论什么程序,最终都是会转换为数据的形式存储在存储器中,要执行相应的程序只需要从存储器中依次取出指令执行。
冯.诺依曼结构的灵魂所在正是这里:减少了硬件的连接,这种设计思想导致了硬件和软件的分离,即硬件设计和程序设计可以分开执行。
冯·诺依曼架构将通用计算机定义为以下 3 个基本原则:
- 采用二进制:指令和数据均采用二进制格式;
- 存储程序:一个计算机程序,不可能只有一条指令,而是由成千上万条指令组成的。指令和数据均存储在存储器中,而不是早期的插线板中,计算机按需从存储器中取指令和取数据;
- 计算机由 5 个硬件组成:运算器、控制器、存储器、输入设备和输出设备。
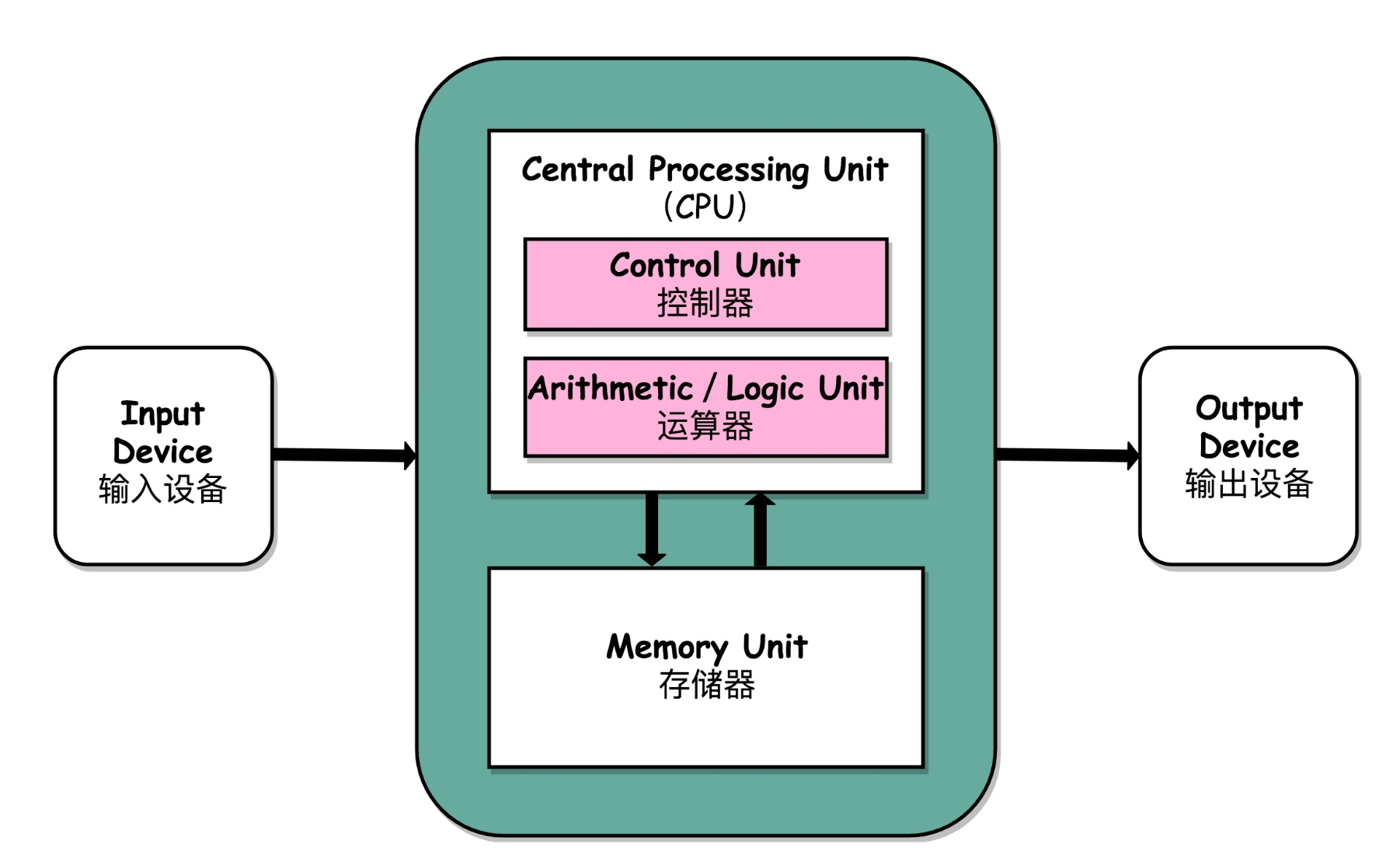
1.3.1 运算器
首先计算机要有运算处理数据的能力,所以需要一个处理单元来完成各种算数运算和逻辑运算,这就是算术逻辑单元(Arithmetic Logic Unit,ALU)。ALU 的主要功能就是在控制信号的作用下,完成加、减、乘、除等算术运算以及与、或、非、异或等逻辑运算以及移位、补位等运算。
运算器的主要部件就是 ALU ,运算器的处理对象是数据,所以数据的长度以及数据的表示方法,对运算器的影响很大。大多数通用计算机是以 16、32 、64 位数据作为运算器一次处理数据的长度。能够对一个数据的所有位同时处理运算器称为并行运算器,一次只能对数据的一个位处理的运算器称为串行运算器。
运算器与其他部分的关系:
计算机运算时,运算器的操作对象和操作种类由控制器决定。运算器操作的数据从内存中读取,处理的结果再写入内存(或者暂时存放在内部寄存器中),而且运算器对内存数据的读写是由控制器来进行的。
1.3.2 控制器
控制器又称为控制单元(Control Unit),是计算机的神经中枢和指挥中心,只有在控制器的控制下,整个计算机才能够有条不紊地工作、自动执行程序。
控制器的工作流程为:从内存中取指令、翻译指令、分析指令,然后根据指令的内存向有关部件发送控制命令,控制相关部件执行指令所包含的操作。
控制器和运算器共同组成中央处理器(Central Processing Unit)简称CPU,CPU 是一块超大规模集成电路,是计算机运算核心和控制核心,CPU 的主要功能是解释计算机指令以及处理数据。
1.3.3 存储器
存储器的主要功能是存储程序和各种数据,并且能够在计算机运行过程高速、自动地完成程序或者数据的存储,存储器是有记忆的设备,而且采用俩种稳定状态的物理器件来记录存储信息,所以计算机中的程序和数据都要转换为二进制代码才可以存储和操作。
存储器可以分为内部存储器(内存)和外部存储器,俩者在计算机系统中各有用处,下面大概介绍一下俩种存储器的特点:
1.内部存储器
内部存储器称为内存或者主存,是用来存放欲执行的程序和数据。
在计算机内部,程序和数据都是以二进制代码的形式存储的,它们均以字节为单位(8位)存储在存储器中,一个字节占用一个存储单元,并且每个存储单元都有唯一的地址号。
这里以字节(8位)为存储单元,就与上面运算器的操作数据的大小联系起来了,16、32、64都是8的倍数
CPU 可以直接使用指令对内部存储器按照地址进行读写俩种操作,
读:将内存中某个存储单元的内容读出,送入 CPU 的某个寄存器中;
写:在控制器的控制下,将 CPU 中某寄存器内容传到某个存储单元中。
要注意,内存中的数据和地址码都是二进制数,但是俩者是不同的,一个地址可以指向一个存储单元,地址是存储单元的位置,数据是存储单元的内容,数据可以是操作码、可以是 CPU 要处理阿数据、也可以是数据的地址,地址码的长度由内存单元的个数确定。
内存的存取速度会直接影响计算机的运算速度,由于 CPU 是高速器件,但是 CPU 的速度是受制于内存的存取速度的,所以为了解决 CPU 和内存速度不匹配的问题,在 CPU 和内存直接设置了一种高速缓冲存储器Cache。 Cache 是计算机中的一个高速小容量存储器,其中存放的是 CPU 近期要执行的指令和数据,其存取速度可以和CPU的速度匹配,一般采用静态 RAM 充当 Cache。
内存按工作方式的不同又可以分为俩部分:
RAM:随机存储器,可以被 CPU 随机读取,一般存放 CPU 将要执行的程序、数据,断电丢失数据,作为线性排列存储区域,存储的数据单位为一个二进制位(bit),最小的存储单位叫做字节(byte)每个字节对应一个内存地址,1byte=8bit。
ROM:只读存储器,只能被 CPU 读,不能轻易被 CPU 写,用来存放永久性的程序和数据,比如:系统引导程序、监控程序等。具有掉电非易失性。
2.外部存储器
外部存储器主要来存放”暂时“用不着的程序和数据,可以和内存交换数据。
一般是磁盘、光盘、U盘、硬盘等。
1.3.4 输入输出设备
实际上我们操作计算机都是与输入输出设备在打交道。
鼠标键盘是输入设备、显示器是输出设备;
手机触摸屏即时输入设备又是输出设备;
服务器中网卡既是输入设备又是输出设备;
所有的计算机程序都可以抽象为输入设备读取信息,通过 CPU 来执行存储在存储器中的程序,结果通过输出设备反馈给用户。
经过发展现代计算机结构如下:中央处理器(CPU)、内存、输入设备、输出设备、总线。
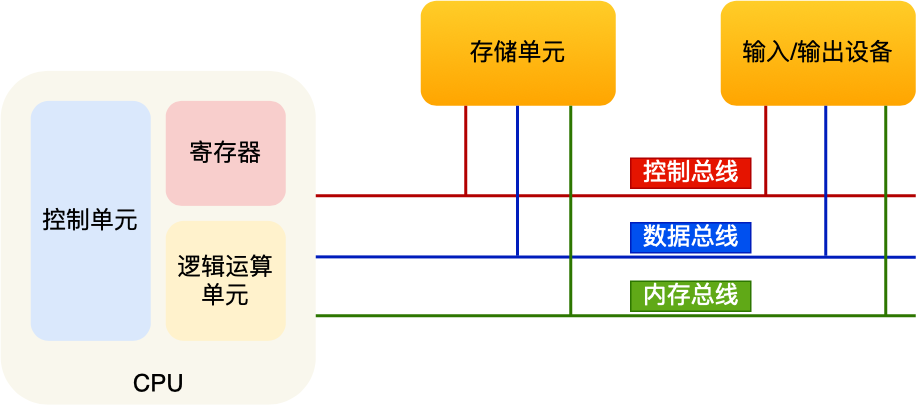
总线(控制总线,数据总线,内存总线)
总线(Bus)是计算机各种功能部件之间传送信息的公共通信干线,它是由导线组成的传输线束, 按照计算机所传输的信息种类,计算机的总线可以划分为数据总线、地址总线和控制总线,分别用来传输数据、数据地址和控制信号。总线是一种内部结构,它是CPU、内存、输入、输出设备传递信息的公用通道,主机的各个部件通过总线相连接,外部设备通过相应的接口电路再与总线相连接,从而形成了计算机硬件系统。
总结一下,冯.诺依曼结构消除了原始计算机体系中,只能依靠硬件控制程序的状况(程序作为控制器的一部分,作为硬件存在),将程序编码存储在存储器中,实现了可编程的计算机功能,实现了硬件设计和程序设计的分离,大大促进了计算机的发展。
2 计算机是如何执行程序代码的
在前面,我们知道了程序在图灵机的执行过程,接下来我们来看看程序在冯诺依曼模型上是怎么执行的。
CPU 只能识别机器码,所以不管是哪位类型编程语言,不管经历了什么样的编译,解释过程,最终都是要交给CPU 来执行。
那么 CPU 是如何执行程序的呢?
程序实际上是一条一条指令,程序的运行过程就是 CPU 一步一步执行每一条指令。
我们都知道,CPU的读写速度是纳秒级,CPU 读取内存数据耗时是 CPU 相关操作耗时的千倍,基本上到达了微秒级别。
如果是去执行 IO 操作,即使是较快的 SSD,耗时也是内存操作耗时的千倍,基本上到达了毫秒级别;
如果是在更慢的磁盘上执行 IO 操作,耗时也是 SSD 操作耗时的百倍,达到了毫秒级别;
若是需要执行网络请求去获取数据,则耗时是 SSD 操作耗时的千倍,稍有不慎就会上到秒的级别
综上所述
获取数据的存储来源每上一个等级,时间量级也要跟着上一个等级
CPU. -> 内存 -> SSD -> 磁盘 -> 网络
纳秒 -> 微秒 -> 毫秒 -> 毫秒 -> 秒CPU 和内存之间的速度瓶颈被称为冯诺依曼瓶颈,为解决这个问题,寄存器和(L1,L2,L3)三级缓存诞生了。
寄存器的硬件设计高成本高功耗,且离CPU的距离非常近(通常寄存器集成在CPU上),寄存器读写速度与CPU有可匹敌,读写速度非常之快,所以数据的计算之前将数据从内存读入寄存器,计算之后再从寄存器写入内存,计算过程中的临时结果的存取由寄存器代替内存管理,会极大减少CPU与慢速内存的交互。
不同CPU包含的寄存器种类不同,常见的寄存器如下:
1)通用寄存器:AX,BX,CX,DX
通用寄存器可用于传送和暂存数据,也可参与算术逻辑运算,并保存运算结果。
AX(Accumulator)-累加器:常用于存放算术(乘除)、逻辑运算等操作。另外,所有的I/O指令都要使用累加器与外设接口传递数据。
BX(Base Register)-基址寄存器:DS段中的数据指针,常用来存放访问内存时的地址。
CX(Count Register)-计数寄存器:在循环、字符串操作指令中用作计数器,用于控制循环次数。
DX(Data Register)-数据寄存器:在寄存器间接寻址中的I/O指令中存放I/O端口的地址。
2)指针寄存器:BP,SP,SI,DI,IP
主要用来保存当前正在执行的一条指令。
BP(Base Pointer Register)和 SP(Stack Pointer Register)是用于存储栈空间地址的寄存器,SP存储栈顶地址,BP比较特殊,一般存储栈中一个栈帧的栈底地址。
SI(Source Index Register)源地址寄存器和 DI(Destination Index Register)目的地址寄存器,分别用来存储读取和写入数据的内存地址。
IP(Instruction Pointer Register)指令指针寄存器存储下一条将要执行的指令的内存地址,CS 和IP 两个寄存器中存储的内容通过计算,能得到一个真正的物理内存地址。
3)段寄存器:CS,DS,SS
段寄存器是因为对内存的分段管理而设置的。计算机需要对内存分段,以分配给不同的程序使用(类似于硬盘分页)
程序由一组指令和一堆数据组成。指令存储在某块内存中(这块内存被称为代码段),由 CPU 逐一读取执行。数据也存储在某块内存中(这块内存被称为数据段)。指令执行的过程中,会操作(读取或写入)这块内存中的数据。
CS(Code Segment Register)代码段地址寄存器存储了代码段的起始地址。CS 和 IP 两个寄存器中存储的内容通过计算,能得到一个真正的物理内存地址。
PC寄存器(Program Counter Register)实际上是一个抽象概念,CS 寄存器和 IP 寄存器是具体寄存器的名称。通过这两个寄存器,可以得知对于存储下一条将要执行的指令的地址。
DS(Data Segment Register)数据段地址寄存器存储了数据段的起始地址,同理,它跟 DI 或 SI 结合才能确定一个数据段中的内存地址。
SS(Stack Segment Register)栈寄存器存储的是栈的起始地址,同理,它跟 SP 结合才能确定栈顶的内存地址,跟 BP 结合才能确定栈中某个中间位置的内存地址。
4)指令寄存器:IR
IR(Instruction Register)指令寄存器用来存放当前正在执行的指令。指令为一串二进制码,指令译码器需要从指令中解析出操作码和操作地址或操作数。所以,指令需要暂存在指令寄存器中等待译码处理。
5)标志寄存器
FR(Flag Register)标志寄存器,也叫做程序状态字寄存器(Program Status Word,PSW),在这个寄存器中的每一个二进制位记录一类状态,主要用于反映处理器的状态和ALU运算结果的某些特征及控制指令的执行。
以上寄存器都是用来辅助完成CPU的各种指令。注意,以上是 16 位的寄存器,32 位的寄存器名称在对应的16 位寄存器名称前加E(例如EAX,EBP,ESP,EIP),64 位的寄存器名称在对应的 16 位寄存器名称前加R(例如RAX,RBP,RSP,RIP)
CPU 执行程序的过程如下:
- 首先,操作系统会把机器码,加载到内存中的代码段,将代码中变量等数据放入内存中的数据段,并且设置好各个寄存器的初始值,如 DS、CS 等。IP 寄存器中存储代码段中第一条指令的内存地址相对于CS的偏移地址。数据准备好后通过【数据总线】将指令数据传给 CPU。
CPU 收到内存传来的数据后,根据 PC 寄存器(CS寄存器和IP寄存器的总称)存储的内存地址,从对应的内存单元中取出一条 CPU 指令,放到 IR 指令寄存器中,CPU 分析 IR 指令寄存器中的指令,确定指令的类型和参数,如果是计算类型的指令,就把指令交给【逻辑运算单元(运算器)】运算;如果是存储类型的指令,则交由【控制单元】执行;
举例说明:假设指令是一条加法指令,控制器通过总线发送指令给运算器告知“你要准备运算了”,运算器接收指令,需要获取数据,于是通过总线发送命令给存储器告知“运算器要获取数据了”,存储器接收命令后,根据地址计算将运算所需的数据取出来,交给运算器做加法,然后将结果给存储器,最后控制器发送控制命令给存储器和输出设备告知指令执行结束,存储器将结果传递给输出设备打印。
- CPU 执行完指令后,将IP寄存器中的地址 + 4(也就是下一条指令在代码段中的偏移地址。内存中的每一个字节都对应一个地址。对于 32 位 CPU ,一条指令长度为4字节,下一条指令地址 = 当前指令地址 + 4。对于 64 位 CPU ,一条指令长度是 8 字节,下一条指令地址=当前指令地址 + 8),一条指令执行完成之后,再通过 PC 寄存器中的地址,取下一条指令继续执行。循环往复,直到所有的指令都执行完成。
简单总结一下就是,一个程序执行的时候,CPU 会根据程序计数器里的内存地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。
CPU 从程序计数器读取指令、到执行、再到下一条指令,这个过程会不断循环,直到程序执行结束,这个不断循环的过程被称为 CPU 的指令周期。
3. 编译型语言 or 解释型语言?
上文中我们了解了计算机是如何执行程序的,我们知道 CPU 只能识别机器码。
在早期计算机发展史,程序员直接使用机器码来编写程序,机器码为二进制,可读性不好且非常复杂,于是汇编语言诞生了,汇编语言由一组汇编指令组成,汇编指令与 CPU 指令一一对应,但汇编指令采用字符串而非二进制表示指令,可读性比机器码好些,但汇编语言编写的程序,需要经过“翻译”成机器码才会被 CPU 执行。
而计算机语言发展至如今,像 Java,C++,Python 这种高级语言所编写的代码,仍需要“翻译”成机器码,才能被 CPU 所识别执行,具体的编程语言翻译的类型不同。
总的来说分为以下 3 类
- 编译型语言
- 解释型语言
- 混合型语言
下面让我们来详细了解它们。
3.1 编译型语言
以 C++ 为代表,代码被编译成机器码(可执行文件)后,由 CPU 逐条执行,执行效率较高,但由于 CPU 类型不同导致所支持的 CPU 指令集不同,操作系统不同导致程序所引用系统 API 不同,这样造成编译之后的可执行文件只能在特定的操作系统或机器上执行,否则可能无法执行。
3.2 解释型语言
以 Python 为代表,代码是在执行的过程中,由 Python 解释器逐条取出程序中的代码,逐条解释成机器码后交给 CPU 执行,CPU 执行完当前机器码后,再取出下一条代码,重复上述流程。
以上流程称为解释执行,边解释边执行。
相较于编译型语言,解释型语言边解释边执行的机制,执行速度略慢,但可移植性好,由 Python 解释器根据不同的操作系统或机器,解释成相对应的 CPU 指令码,从而达到一次编写,到处运行的效果。
3.3 混合型语言
以 Java 为代表,Java 编译器先将程序代码(.java)编译成字节码(.class),再有 Java 虚拟机(JVM)解释执行,逐行取出字节码,翻译成机器码,在交由 CPU 执行。
字节码作为中间状态和平台无关,Java 虚拟机会将反复多次执行的字节码编译成机器码后缓存下来作为热点数据,以避免热点字节码反复编译,这个过程被称为 JIT 编译(JustInTime Compile 即时编译),这样可节省解释执行时间。加上从字节码翻译成机器码的过程,会比从高级语言翻译成机器码的耗时少,所以这样的机制造就了 Java 程序的可移植性高,且执行效率不慢。
总的来说混合型语言既包含了编译执行的过程也包含了解释执行的过程,集两家所长。
4. Java代码的执行过程
上面我们了解了 Java 作为混合型语言的大概执行流程,也明白了 Java 语言一次编写,到处运行,跨平台的特性,功劳离不开 Java 虚拟机(JVM)的存在,接下来我们来细说 Java 编译执行过程。
其中流程包括前端编译,类加载,解释执行,JIT 编译执行,AOT 编译。
4.1 前端编译
前端编译是只通过 javac 编译器将 .java 文件编译成 .class 文件的过程,前端编译除了经过词法分析,语法分析,语义分析外还做了注解处理和解语法糖处理。
注解处理
从 JDK6 开始,javac 编译器开始支持 JSR269(Pluggable Annotation Processing API)规范。我们只需要按照这个规范来开发注解插件(插件包含定义注解、使用注解、以及对应的注解处理器三部分内容),那么,javac 编译器在执行前端编译时,就会调用注解插件执行相应的注解处理器代码。
我们在开发中经常用到的 Lombook 插件,便是按照 JSR269 规范开发的注解插件。在编译代码时,javac 编译器会调用 Lombook 插件的注解处理器,注解处理器根据 @getter、@setter 等注解,为类、成员变量生成 getter、setter 等方法。Lombook 插件中定义的注解大部分都是 SOURCE 级别的,也就是JVM也不会感知到语法糖。语法糖仅存在于源码中。当代码编译成字节码之后,这些注解便没有存在的意义了。毕竟 JVM 并不关心 getter、setter 方法来自于程序员手敲,还是 Lombook 注解。
语法糖处理
Java 为了提高开发效率,提供了很多语法糖(对已经存在的基本语法的二次封装)目的是提高易用性,在执行前端编译时,编译器会将语法糖解封装为基本语法。
字节码并不包含语法糖,JVM 也不会感知到语法糖。语法糖仅存在于源码中。
常见的语法糖有
- 泛型
- 包装类自动装箱与拆箱
- 增强for循环
- 方法变长参数
- 枚举
- 内部类
- 条件编译
- 断言
- Lambda表达式
- 字符串+号语法
- switch-case对String和枚举类的支持
- 等等
以泛型为例说明
泛型只存在于源码中,编译时会进行类型擦除,也就是说不管是List
以包装类自动装箱拆箱为例说明
Integer count = 1; // 装箱
int temp = count; // 拆箱通过jad反编译后发现底层实现如下:
Integer count = Integer.valueof(1);
int i = count.intValue();由此发现自动装箱底层相当于执行了 Integer 的 valueof 方法。
自动拆箱底层相当于执行了 Integer 的 intValue 方法。
以增强for循环为例说明
for(int index : list){
System.out.println("" + index);
}通过jad反编译后发现底层实现如下:
Iterator<Integer> iterator = list.iterator();
while(iterator.hasNext()){
System.out.println("" + iterator.next());
}底层实现实际依赖迭代器。
变长方法参数实际底层实现是编译器在编译源码的时候将变长参数部分转换成了 Java 数组
枚举类型也只是编译器编译成普通的 class 类,继承java.lang.Enum,并被 final 关键字修饰,在Java 的字节码结构中,并没有枚举类型。
内部类编译完成,编译器就会为内部类生成一个单独的 class 文件,名为outer$innter.class。
条件编译是通过编译器的优化原则实现的:如果 if 的条件是 false,则在编译时忽略这个 if 语句。 忽略未使用的变量。
断言的底层实现就是if语言,如果断言结果为 true,则什么都不做,程序继续执行,如果断言结果 false,则程序抛出 AssertError 来打断程序的执行。
字符串+号语法
如果在编译期能确定字符相加的结果,则会进行编译期优化。
例如:
String s = "a" + "b";
优化为
String s = "ab";运行时,两个字符串 str1, str2 的拼接首先会 new 一个 StringBuilder 对象,然后分别对字符串进行append 操作,最后调用toString()方法。
4.2 类加载
Java 程序执行过程中,类的字节码按需被加载到内存中,也就是说当第一次创建某个类的对象或调用某个类的方法时,这个类才会被加载到内存中,加载后一直保存在内存中。
类加载遵循双亲委派机制,不同的类由不同的类加载器加载,类加载过程被分为验证,准备,解析,初始化。
4.2.1 字节码
Java 字节码是什么样子,我们借助一段简单的代码来看一看。
/**
* @description: HelloClass
* @Author MRyan
* @Version 1.0
*/
public class HelloClass {
private static String str = "Hello Class";
public static String get() {
return str;
}
}经过 javac 编译成 class 后,通过 javap 工具对其反编译结果如下:
Classfile /Users/ryan/ProgramData/码农翻身/Mine/mlearn/src/main/java/cn/wormholestack/mlearn/jvm/HelloClass.class
Last modified 2022-11-27; size 410 bytes
MD5 checksum c2510b3273939199f415f75260d0630a
Compiled from "Helloclass.java"
public class cn.wormholestack.mlearn.jvm.HelloClass
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
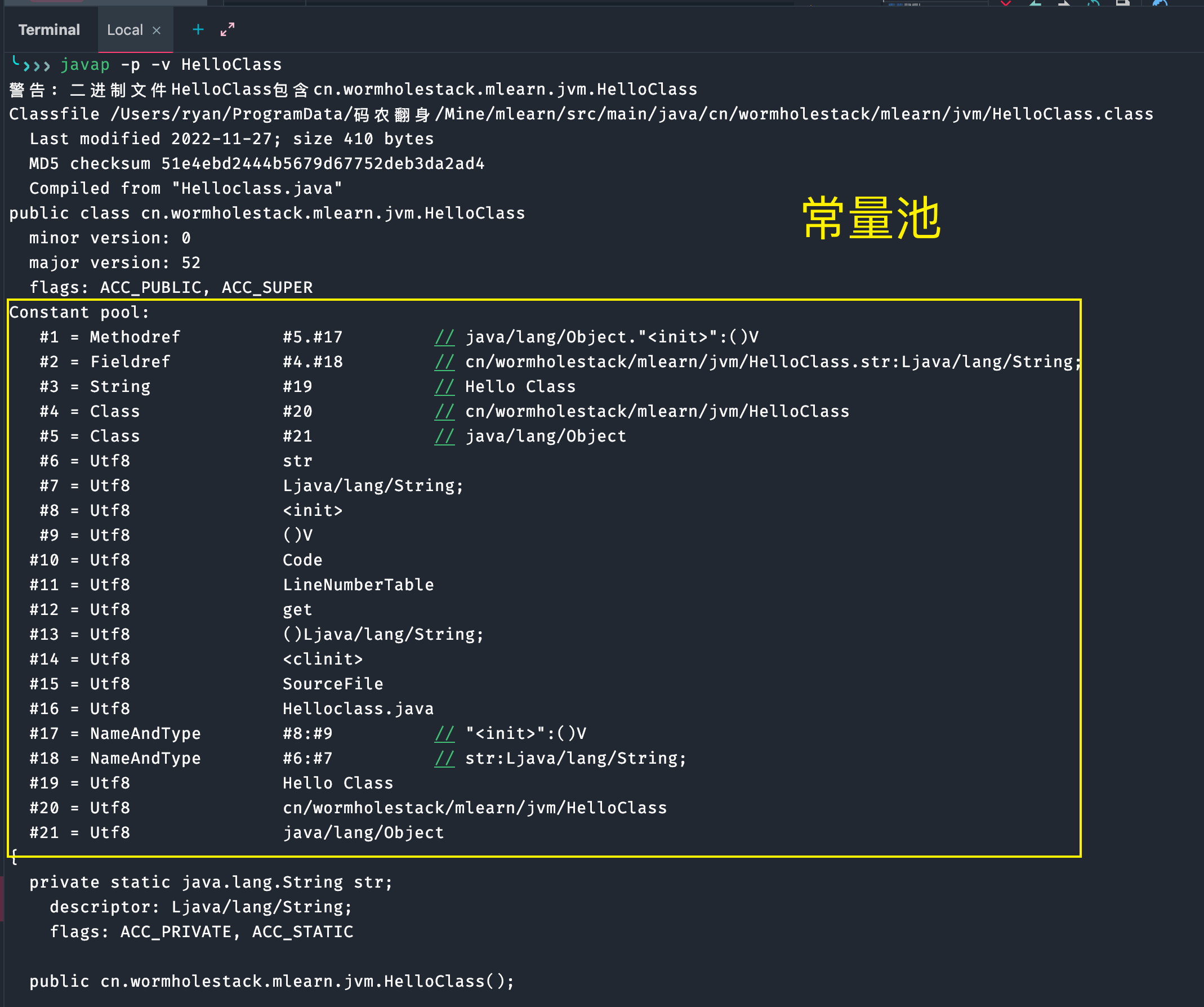
Constant pool:
#1 = Methodref #5.#17 // java/lang/Object."<init>":()V
#2 = Fieldref #4.#18 // cn/wormholestack/mlearn/jvm/HelloClass.str:Ljava/lang/String;
#3 = String #19 // Hello Class
#4 = Class #20 // cn/wormholestack/mlearn/jvm/HelloClass
#5 = Class #21 // java/lang/Object
#6 = Utf8 str
#7 = Utf8 Ljava/lang/String;
#8 = Utf8 <init>
#9 = Utf8 ()V
#10 = Utf8 Code
#11 = Utf8 LineNumberTable
#12 = Utf8 get
#13 = Utf8 ()Ljava/lang/String;
#14 = Utf8 <clinit>
#15 = Utf8 SourceFile
#16 = Utf8 Helloclass.java
#17 = NameAndType #8:#9 // "<init>":()V
#18 = NameAndType #6:#7 // str:Ljava/lang/String;
#19 = Utf8 Hello Class
#20 = Utf8 cn/wormholestack/mlearn/jvm/HelloClass
#21 = Utf8 java/lang/Object
{
private static java.lang.String str;
descriptor: Ljava/lang/String;
flags: ACC_PRIVATE, ACC_STATIC
public cn.wormholestack.mlearn.jvm.HelloClass();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 9: 0
public static java.lang.String get();
descriptor: ()Ljava/lang/String;
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=0, args_size=0
0: getstatic #2 // Field str:Ljava/lang/String;
3: areturn
LineNumberTable:
line 13: 0
static {};
descriptor: ()V
flags: ACC_STATIC通过 jclasslib 可以直观的看到当前字节码文件的类信息,常量池,方法区等信息

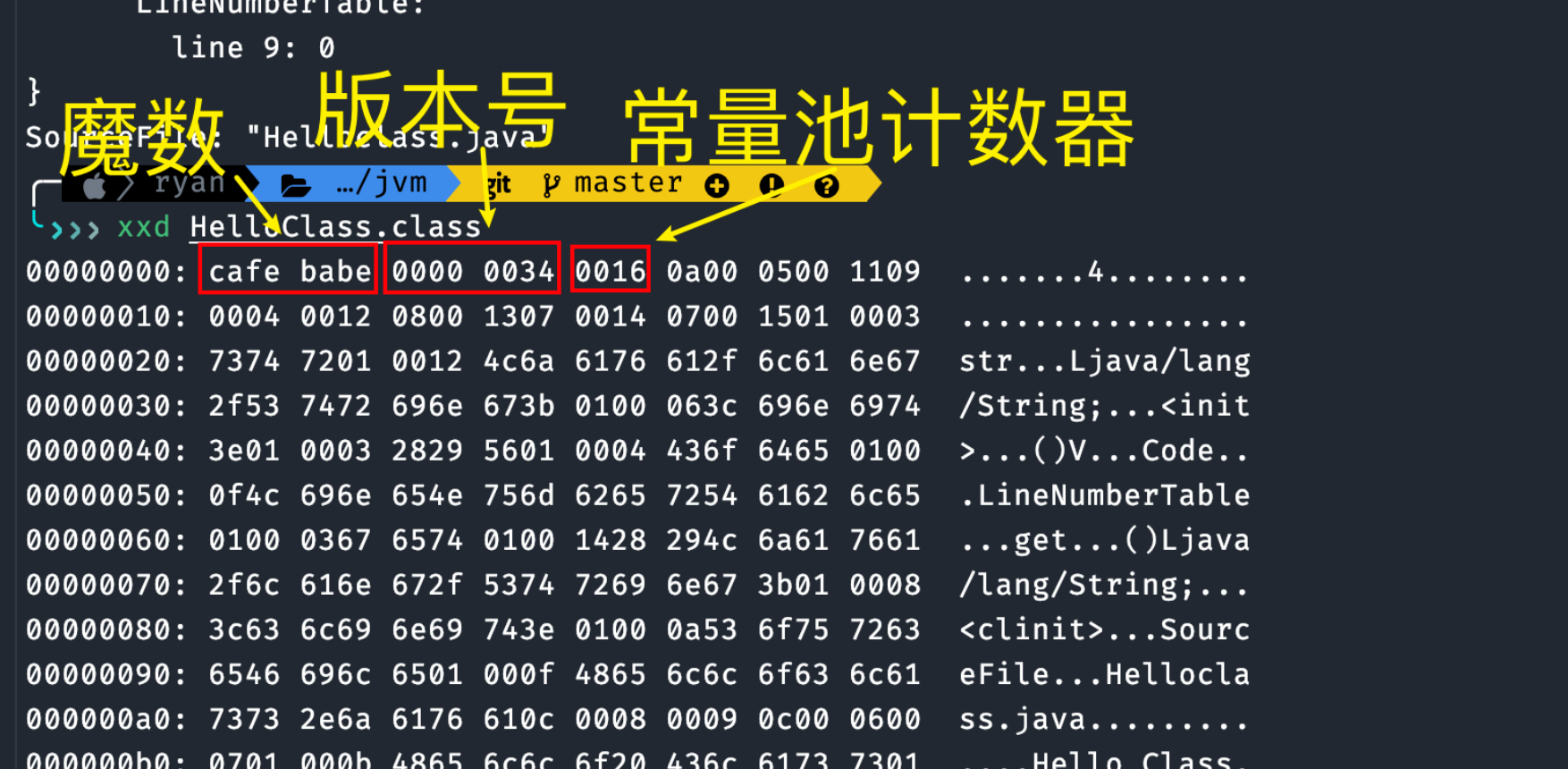
通过 xxd HelloClass.class 命令查看一下这个字节码文件。
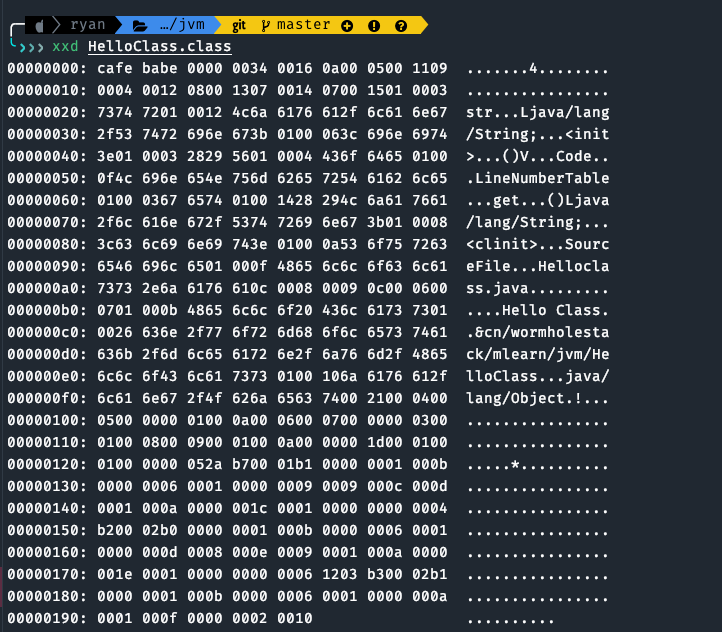
JVM 规范要求每一个字节码文件都要由十部分按照固定的顺序组成。

结合上面3张图,字节码文件包含的结构属性如下:
魔数(Magic):
第一行中有一串特殊的字符 cafebabe,它就是一个魔数,是 JVM 识别 class 文件的标志,JVM 会在验证阶段检查 class 文件是否以该魔数开头,如果不是则会抛出 ClassFormatError
你可能很好奇,为什么用cafebabe当做魔数,事实上它并没有什么特别的意义。
James Gosling(Java编程语言之父)的解释如下:
“我和小伙伴们经常去一个叫 St Michael’s Alley 的地方吃午餐。根据当地传说, 在深暗的过去,Grateful Dead在出名前曾在此地表演. 这绝对是一个因 Grateful Dead Kinda Place 而闻名的地方。Jerry去世时, 他们进行了祭奠.我们经常去那里, 称这个地方为 Cafe Dead。
可以看到,这是一个十六进制数. 那时候我正好需要维护一些文件的编码格式,需要用到两个魔数,一个用于对象持久化文件, 另一个用于类文件. 于是我就用 cafe dead 作为对象持久化文件的魔数, 并选中了cafe babe作为 class 文件标识。”

版本号(Version):
紧跟着魔数后面的四个字节 0000 0034 分别表示副版本号和主版本号。也就是说,主版本号为 52(0x37 的十进制),也就是 Java 8 对应的版本号,副版本号为 0。
常量池(constant_pool):
紧跟在版本号之后的是常量池入口,字符串常量和较大的整数都会存储在常量池中,当使用这些数值时,会根据常量池中的索引来查找。
常量池中存储两类常量:字面量与符号引用。
字面量:比较接近于Java语言层面的常量概念,如文本字符串、声明为final的常量值等
符号引用:如类和接口的全局限定名、字段的名称和描述符、方法的名称和描述符。
常量池整体上分为两部分:常量池计数器以及常量池数据区,

- 常量池计数器(constant_pool_count):由于常量的数量不固定,所以需要先放置两个字节来表示常量池容量计数值。图 2 中示例代码的字节码前 10 个字节,将十六进制的 16 转化为十进制值为 22,排除掉下标 “0”,也就是说,这个类文件中共有 21 个常量。
- 常量池数据区:数据区是由(constant_pool_count-1)个 cp_info 结构组成,一个 cp_info 结构对应一个常量。在字节码中共有 14 种类型的 cp_info,每种类型的结构都是固定的。

具体以 CONSTANT_utf8_info 为例,它的结构如下左侧所示。首先一个字节 “tag”,它的值取自上图6中对应项的 Tag,由于它的类型是 utf8_info ,所以值为 “01”。接下来两个字节标识该字符串的长度 Length,然后 Length 个字节为这个字符串具体的值。从反编译结果的字节码中摘取一个 cp_info 结构,如下图右侧所示。将它翻译过来后,其含义为:该常量类型为 utf8 字符串,长度为一字节,数据为 “a”。

其他类型的 cp_info 结构在本文不再赘述,整体结构大同小异,都是先通过 Tag 来标识类型,然后后续 n个字节来描述长度和(或)数据。
注意此常量池被称为class文件常量池,不要混淆,它可以理解为一个元信息资源仓库(字面量,符号引用),由于java的特殊机制,class文件没法保存各个方法或字段最终的内存布局信息,只能通过JVM加载字节码时动态链接,在类加载解析阶段从常量池获取对应的符号引用翻译成可直接访问内存储地址的直接引用,同时会将class文件常量池中的内容导入方法区中的运行时常量池,在这个过程中通过cp_info来判定数据结构类型。
访问标识(access_flag):
常量池结束之后的两个字节,描述该 Class 是类还是接口,以及是否被 Public、Abstract、Final等修饰符修饰。JVM 规范规定了如下图的访问标志(Access_Flag)。需要注意的是,JVM并没有穷举所有的访问标志,而是使用按位或操作来进行描述的,比如某个类的修饰符为 Public Final,则对应的访问修饰符的值为 ACC_PUBLIC | ACC_FINAL,即 0x0001 | 0x0010=0x0011。

当前类索引(this_class):
访问标志后的两个字节,描述的是当前类的全限定名。这两个字节保存的值为常量池中的索引值,根据索引值就能在常量池中找到这个类的全限定名。
父类索引(super_class):
当前类索引后的两个字节,描述父类的全限定名,同上,保存的也是常量池中的索引值。
接口索引(interfaces):
父类索引后为两字节的接口计数器,描述了该类或父类实现的接口数量。紧接着的n个字节是所有接口名称的字符串常量的索引值。
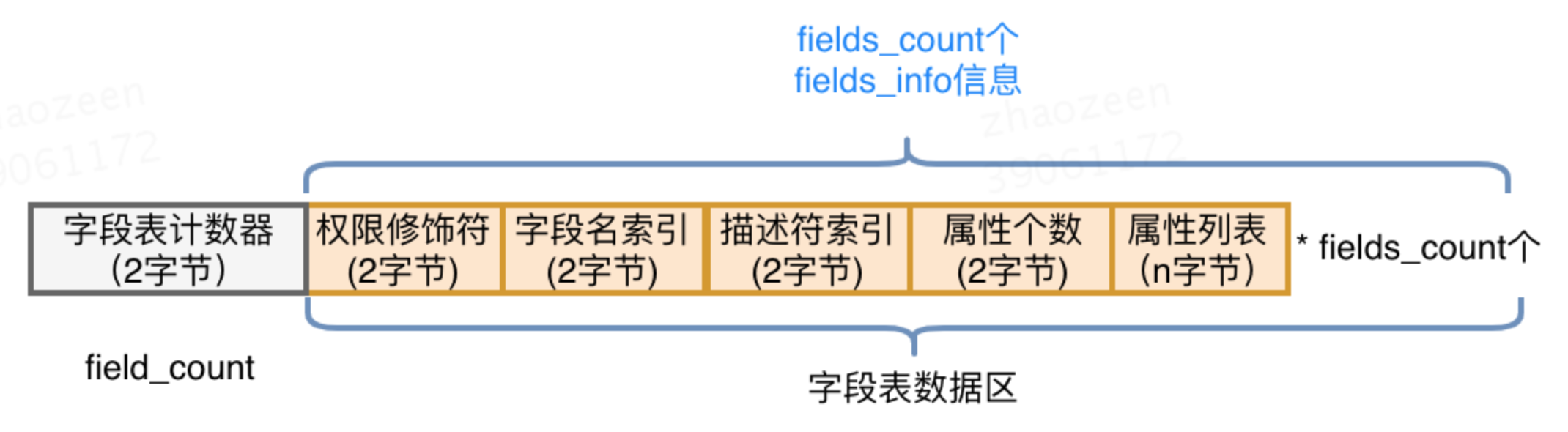
字段表(fields):
字段表用于描述类和接口中声明的变量,包含类级别的变量以及实例变量,但是不包含方法内部声明的局部变量。字段表也分为两部分,第一部分为两个字节,描述字段个数;第二部分是每个字段的详细信息fields_info。字段表结构如下图


方法表(methods):
直接看反编译后的的内容,有兴趣的读者可以去研究下字节码 16 进制文件对应的方法表。
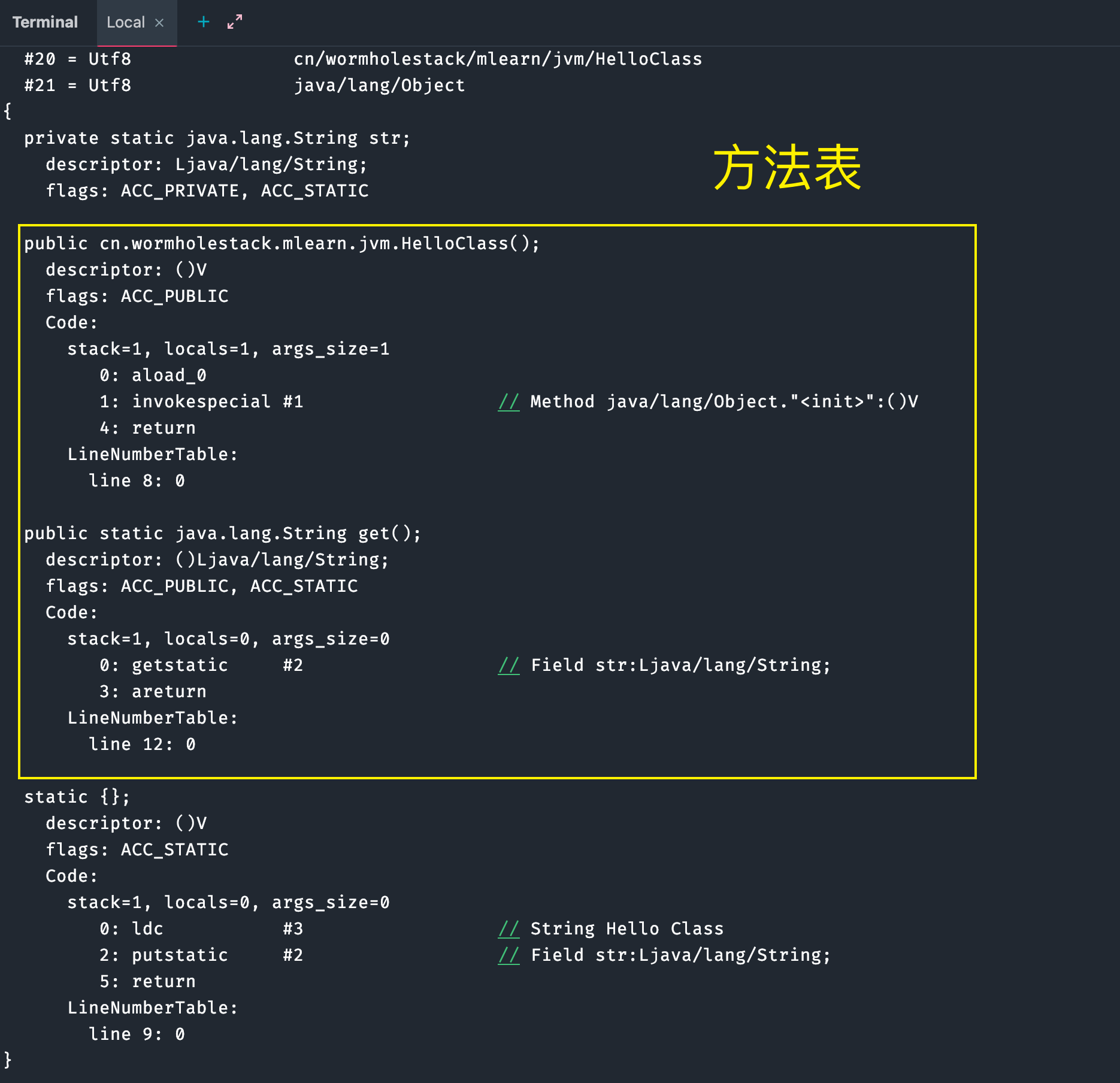
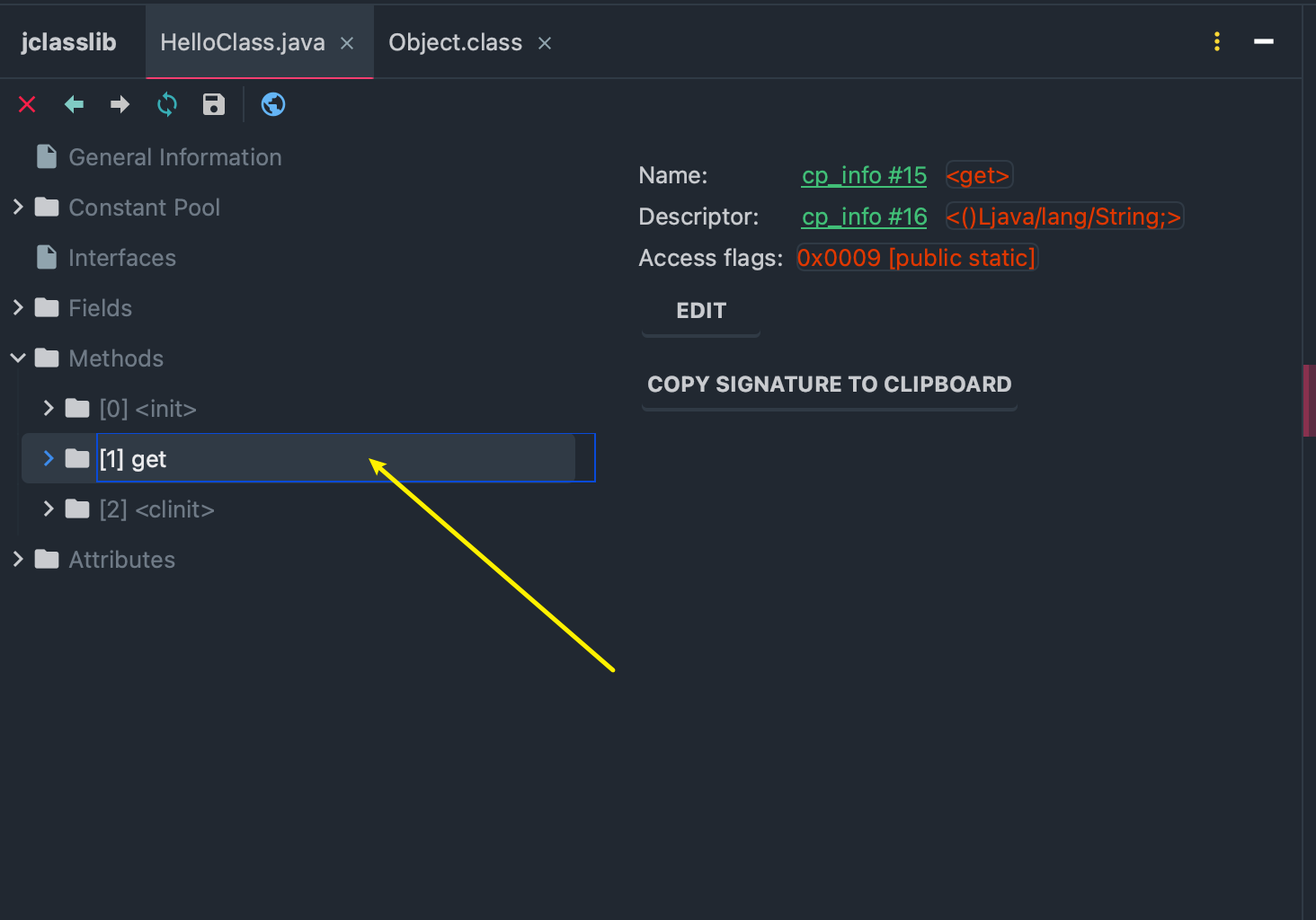
我们可以看到构造函数及程序中定义的 get 方法
其中 Code 内主要属性为:
stack: 最大操作数栈深度,JVM 运行时会根据这个值来分配栈帧(Frame)中的操作栈深度,此处为 1
locals: 局部变量所需的存储空间,单位为 Slot, Slot 是虚拟机为局部变量分配内存时所使用的最小单位,为 4 个字节大小。方法参数(包括实例方法中的隐藏参数 this),显示异常处理器的参数( try catch 中的 catch 块所定义的异常),方法体中定义的局部变量都需要使用局部变量表来存放。值得一提的是,locals 的大小并不一定等于所有局部变量所占的 Slot 之和,因为局部变量中的 Slot 是可以重用的。
args_size: 方法参数的个数,这里是 0,每个实例方法都会有一个隐藏参数 this,但仅针对非Static方法而言。
attribute_info: 方法体内容,0,1,4 为字节码"行号",该段代码的意思是将第一个引用类型本地变量推送至栈顶,然后执行该类型的实例方法,也就是常量池存放的第一个变量,也就是注释里的java/lang/Object."":()V, 然后执行返回语句,结束方法。
LineNumberTable:行号表,将 Code 区的操作码和源代码中的行号对应,Debug 时会起到作用(源代码走一行,需要走多少个 JVM 指令操作码)。
LocalVariableTable: 本地变量表,包含This和局部变量,之所以可以在每一个方法内部都可以调用 This,是因为 JVM 将 This 作为每一个方法的第一个参数隐式进行传入。当然,这是针对非 Static方法而言。
附加属性表(attributes)
字节码的最后一部分,该项存放了在该文件中类或接口所定义属性的基本信息。
4.2.2 验证
这一阶段主要是验证所生成的类字节码格式是否符合 JVM 规范,避免由于类字节码来源不可控导致安全问题或恶意篡改所做的合法性校验。
4.2.3 准备
在准备阶段,虚拟机为类的静态变量分配内存,并将其初始化为默认值。对于 static final 修饰的静态常量,虚拟机直接将其初始化为指定值。
例如:private static final int count = 1,JVM在准备阶段将变量count初始化为1。
对于只有static修饰的静态变量,JVM将其初始化为所属类型的默认值而非指定值,
例如:private static int count = 1,JVM会在准备阶段将变量 count 初始化为int 类型的默认值 0 ,指定值 1 会在初始化阶段赋值给变量 count 。
静态变量归属于类,非静态变量归属于对象,因此,在类的加载过程中,虚拟机只处理类的静态变量,类的非静态变量在对象的创建过程中处理,并且存储在对象所占用的内存空间中。
4.2.4 解析
类字节码常量池中的符号引用转换为直接引用,常量池中存储了所涉及的类,方法,变量等描述符,通过此步将描述符转换为可以直接访问内存存储地址的直接引用。
4.2.5 初始化
虚拟机会执行静态变量的初始化,初始化语句,静态代码块
4.3 解释执行
对于 Java 语言来说,经过前段编译后的 .class 字节码文件,加载到内存无法被 CPU 直接执行,依赖于 JVM 虚拟机将字节码逐条取出,一遍将其解释为机器码,一遍交给 CPU 执行。
举例说明:
如下代码 JVM 执行 Main 方法,执行 new HelloClass()创建HelloClass类对象时,JVM 发现内存中没有此类的字节码信息,于是通过类加载器在 classpath 对应的路径下寻找 HelloClass 文件,将其加载至内存中,虚拟机会根据类的字节码在堆中创建对象,在执行 helloClass.get()方法时,JVM 会根据 HelloClass 对象类指针找到内存中的 HelloClass 类,在类的方法表中查找 get 方法对应的字节码,然后逐句解释执行。
/**
* @description: HelloClass
* @Author MRyan
* @Version 1.0
*/
public class HelloClass {
private String str = "Hello Class";
public String get() {
return str;
}
}
class Main {
public static void main(String[] args) {
HelloClass helloClass = new HelloClass();
System.out.println(helloClass.get());
}
}这里简单提一嘴类加载器的双亲委派机制
类加载由类加载器完成,JVM定义了几种不同类型的类加载器
- 启动类加载器(BootStrap ClassLoader) 负责加载jre/lib/rt.jar包中类
- 扩展类加载器(Extension ClassLoader) 负责加载jre/lib/ext目录下jar包中类
- 应用程序类加载器(Application ClassLoader) 负责加载其他classpath指定路径下(除启动,扩展类加载器负责的路径)的类
JVM无法通过类全限定名来明确由哪个类加载器加载哪个类,这样就会导致重复加载类的情况,所以为了去重,JVM设计了双亲委派机制,虚拟机定义了类加载器的父子关系,并提出如下机制:

当某个类加载器接受到加载类的请求时,如果当前类加载器没有加载过这个类就委托给父类加载器加载此类,如果父类加载器也没有加载过此类,则继续委托给父类的父类加载器加载,知道某个类加载器已经加载过此类结束。如果都没有找到已经加载过此类的类加载器,虚拟机会从上往下请求各个类加载器,如果此类事自己负责的路径下的类则就由它来加载。
4.4 JIT编译
上文有提过,边解释边执行的机制造成程序执行效率并没有编译型语言高,为了解决这个问题,Java 引入了JIT(Just in Time)。
也就是说为 JVM 将热点代码的机器码缓存了起来,让下去执行热点代码的时候可复用,无需解释。
HotSpot 虚拟机支持两种JIT编译器:Client(C1)编译器 Server(C2)编译器,Client 编译器只进行局部的编译优化所以它编译时间短,但是优化程度低,Server编译器进行局部和全局编译优化,所以编译时间长,但优化程度高。常说的 JVM 的两种运行模式其实就是 Client 模式和 Server 模式。
Java7之前,虚拟机对于两者编译器只能二选一,无法同时使用,但Java7引入了分层编译,可以让虚拟机根据不同代码在不同时刻选择不同的编译类型,Java8种默认开启分层编译技术,
JIT的实现是在运行期收集代码运行情况,做热点探测。
那么什么样的代码才算热点代码呢?
- 被多次执行的方法
- 被多次执行的循环
HotSpot虚拟机针对每个方法维护两个计数器,方法调用计数器和回边计数器,分别用来统计方法执行次数和循环执行次数,计数器通过比对动态阈值(动态计算)判定是否为热点代码。
同时为解决随运行时间增长,一直执行的方法总会出现调用次数总高于阈值的时刻,JVM引入了热度衰减机制,超过一定时间限制之后,某方法没有达到阈值,那么使方法的计数器值减半,注意只有方法计数器存在此机制,且可以通过-XX:CounterHalfLifeTime设置超过的时间,通过-XX:UseCounterDecay设置关闭热度衰减机制。
4.5 AOT编译
AOT(Ahead Of Time)即提前编译,C/C++编译型语言便是AOT编译,可以在运行前生成被直接执行的二进制机器码,运行速度快、执行性能表现好,但每次执行前都需要提前编译,开发测试效率低。
Java也支持AOT编译,区别于JIT编译,AOT编译优化属于静态编译优化,而JIT编译优化属于动态编译优化,通常在Java中使用比较少。
5. 小结
到此本文就要收尾了,本文逐步递进,由计算机历史为引,到计算机组成原理,再到Java程序原理,涉及内容较多,但很好理解。
现在回到文章开篇的3个问题,我知道你已经可以完美解答。
参考
https://gist.github.com/hellerbarde/2843375
https://cizixs.com/2017/01/03/how-slow-is-disk-and-network/
https://cloud.tencent.com/developer/article/1729507
https://tech.meituan.com/2019/09/05/java-bytecode-enhancement.html
https://www.zhihu.com/question/23874627
https://en.wikipedia.org/wiki/Colossus_computer
https://en.wikipedia.org/wiki/Delay-line_memory
https://en.wikipedia.org/wiki/EDVAC
https://en.wikipedia.org/wiki/Stored-program_computer
https://en.wikipedia.org/wiki/Java_class_file?spm=a2c6h.12873639.article-detail.6.133d4200KDZW5M
《Java编程之美》
《深入理解Java虚拟机》

作者:MRyan
本文采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。
转载时请注明本文出处及文章链接。本文链接:https://www.wormholestack.com/archives/621/